DevOps + MLOps: Hiring Profiles You Need for Production ML Reliability
Here’s something that doesn’t get talked about enough. Roughly 87% of machine learning models never make it to production. Not because the models are bad. Because the teams building them weren’t set up to actually ship and maintain them. That stat comes from KDnuggets research and similar findings from Gartner and VentureBeat, and it’s been consistent for years. It should bother anyone who’s invested real money into AI.
We work with companies across the U.S. that are going through this exact challenge right now. They hired data scientists. Built some models. Got excited about the results in testing. And then… nothing. The models sit in notebooks. They don’t make it into the products or systems where they’d actually generate value. The missing piece, almost every single time, is the operational layer. The people who know how to get ML models into production, keep them running, and catch problems before customers do.
That’s what MLOps hiring is about. And it’s where DevOps meets machine learning in ways most non-technical leaders don’t fully appreciate until things start breaking.

The six core roles every ML production team needs to operationalize machine learning at scale.
What Is MLOps Hiring, and Why Does It Matter?
MLOps hiring is the process of recruiting professionals who specialize in deploying, monitoring, and maintaining machine learning models in production environments. These roles sit at the intersection of software engineering, data engineering, and machine learning. They require a hybrid skill set that remains in genuinely short supply.
Think of it this way. Traditional software is deterministic. You write code, you test it, you deploy it, and it does the same thing every time. ML models are different. They depend on data. The data changes. Customer behavior shifts. The world doesn’t stay still. So a model that works great today might quietly start giving worse results next month if nobody is watching.
That watching, maintaining, retraining, and pipeline management? That’s what MLOps people do. And most companies don’t have them.
The market for these skills is growing fast. Fortune Business Insights valued the global MLOps market at about $2.3 billion in 2025, projecting it to hit $3.4 billion in 2026. Multiple research firms project compound annual growth between 29% and 41% through the early 2030s. North America accounts for the largest share, around 36% of the global market. That’s a lot of companies trying to hire from the same limited pool of qualified people.
The 6 ML Production Team Roles That Actually Keep Models Running
A production ML system doesn’t run itself. And it definitely doesn’t run on one person. It takes a coordinated set of roles, each handling a different piece of the puzzle. Some of these will be familiar if you’ve built engineering teams before. Others might be new. But understanding what each one does is the first step toward figuring out who you need to hire, and when.
1. MLOps Engineer
This is the role most people think of first, and for good reason. The MLOps Engineer builds and maintains the automated pipelines that take models from training through deployment and into monitoring. They handle data drift detection, retraining triggers, model versioning, and making sure what worked in testing also works when real users are hitting it at scale.
The skill set is broad. Python is a given. Docker and Kubernetes for containerization. CI/CD pipeline design. Cloud platforms like AWS, GCP, or Azure. Experiment tracking tools such as MLflow or Weights & Biases. But the real separator? Understanding the ML lifecycle deeply enough to build tooling that data scientists can actually use without filing a support ticket every time they need to deploy something.
Glassdoor data from January 2026 puts the average U.S. salary at about $161,000, with the typical range between $132,000 and $199,000. Senior MLOps Engineers average over $200,000.
2. ML Platform Engineer
Where the MLOps Engineer works on individual model pipelines, the Platform Engineer builds the shared layer underneath. Feature stores. Model registries. Standardized training environments. Self-service deployment tooling that multiple teams can use without reinventing the wheel every time.
You probably don’t need this role until you have five or more production models and multiple ML teams. But once you hit that threshold, every deployment becomes a custom engineering project without it. And that’s how timelines stretch from days to months.
3. DevOps Engineer (ML-Specialized)
A regular DevOps engineer knows infrastructure automation. But ML workloads bring specific headaches that most DevOps folks haven’t dealt with before. GPU provisioning. Moving massive datasets around. Model artifact storage. Serving infrastructure that handles variable inference latency. It’s different from deploying a web app.
The ML-specialized DevOps engineer bridges that gap. They manage cloud infrastructure, container orchestration, and networking for ML systems specifically. If you already have a strong DevOps team, this might mean upskilling someone internally. Or it might mean hiring someone who’s already done it.
4. Data Engineer
Models are only as good as the data going into them. Full stop. The Data Engineer builds and maintains ingestion, transformation, and validation pipelines that feed production models. Data freshness, quality, consistency. These are the unsexy problems that cause a huge share of production ML failures.
In an ML context, data engineers work much more closely with ML engineers than they would in a traditional analytics setup. The feedback loop between model performance and data quality is constant and tight.
5. ML Engineer
The ML Engineer takes models from experimentation to production-ready code. Optimizing performance. Reducing latency. Handling serialization. Building feature engineering pipelines. Making sure models meet quality thresholds under real conditions, not just in a controlled test environment.
This is a different job from data scientist, and that distinction matters for hiring. We see companies post a data scientist job when what they actually need is an ML engineer who can ship to production. The screening mismatch costs months.
6. ML Architect or Technical Lead
For teams past the early stage, someone needs to own the big picture. Evaluating tooling. Setting standards. Defining how experiments flow into deployment. Making sure the ML infrastructure lines up with broader engineering and business goals.
This is a senior hire. It typically requires deep experience across data science, software engineering, and infrastructure. Companies that skip it end up with fragmented tooling and inconsistent deployment practices as model count grows. We’ve seen it happen more times than we can count.
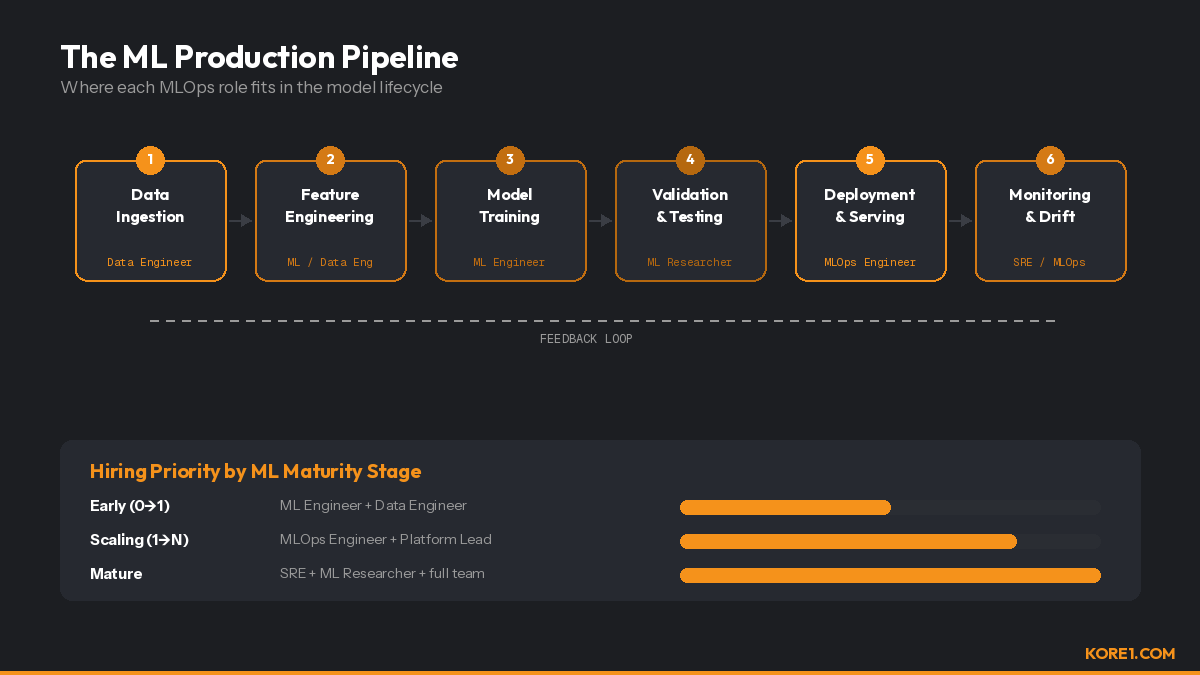
How MLOps roles map to each stage of the ML production pipeline, with hiring priorities by team maturity.
DevOps vs. MLOps vs. ML Platform: What’s the Actual Difference?
This is the question we get most often from hiring managers. Especially non-technical ones who know they need to build out their ML team but aren’t sure which role does what. The short answer is that the overlap is real, but the focus areas are very different.
| Dimension | DevOps Engineer | MLOps Engineer | ML Platform Engineer |
|---|---|---|---|
| Primary focus | Application infrastructure and deployment automation | ML pipeline automation, model monitoring, drift detection | Shared internal tooling and ML infrastructure layer |
| Key tools | Terraform, Jenkins/GitLab CI, Docker, Kubernetes, Prometheus | MLflow, Kubeflow, Weights & Biases, Airflow, SageMaker | Feature stores, model registries, custom orchestration |
| What they deploy | Applications and services | ML models and training pipelines | Internal platforms and self-service tooling |
| What they monitor | Uptime, latency, error rates, throughput | Model accuracy, data drift, concept drift, feature distributions | Platform health, adoption rates, pipeline reliability |
| When to hire | Any team shipping software to production | After 2nd ML engineer or 3+ production models | After 5+ production models across multiple teams |
| U.S. salary range | $120,000 to $175,000 | $130,000 to $200,000+ | $150,000 to $220,000+ |
All three roles use containerization, cloud platforms, and CI/CD automation. That’s the overlap. The difference is what they’re pointing those skills at. DevOps tracks system health. MLOps tracks model behavior. Platform engineering builds the repeatable layer across both.
What we see a lot is companies trying to have their existing DevOps team handle MLOps on the side. It works for a while. Maybe two or three production models. Past that point though, the specialized demands of model monitoring, drift detection, and automated retraining start eating into everyone’s time and nobody does either job well.
When to Hire Each Role: a Practical Staging Guide
Nobody hires all six of these roles at once. Not even well-funded companies. The right approach is to stage your hires based on how many models you’re running and how mature your ML practice is. Here’s roughly how it plays out.
Stage 1: You’re putting your first ML model into production (1 to 2 models)
- Hire a generalist ML Engineer who can handle both modeling and basic deployment work
- Lean on your existing DevOps team for infrastructure
- Data engineering is probably shared with your analytics team at this point
Stage 2: You need things to actually stay reliable (3 to 5 models)
- Hire your first dedicated MLOps Engineer. This is the most commonly delayed hire, and the one that costs companies the most when they wait too long
- Add a Data Engineer focused specifically on ML data pipelines
- Start having your DevOps people learn ML-specific infrastructure patterns
Stage 3: You’re building a real ML platform (5 to 15 models)
- Hire an ML Platform Engineer to standardize tooling so teams stop building everything from scratch
- Bring on a DevOps engineer with specific ML infrastructure experience, or invest in upskilling someone you already have
- An ML Architect or Technical Lead starts making sense here to set standards
Stage 4: Enterprise scale (15+ models, multiple teams)
- Full ML platform team with multiple MLOps and platform engineers
- Dedicated DevOps support for ML infrastructure
- Governance, security, and compliance roles layered in
The biggest pattern we see? Companies waiting way too long to hire that first MLOps Engineer. They usually hit the wall after their second ML engineer joins or around their third production use case. By then, the ML engineers are spending more time writing infrastructure code than doing actual ML work. Which is expensive and frustrating for everyone.
How to Screen Candidates for These Roles (Without Wasting Everyone’s Time)
Screening MLOps and production ML candidates is not the same as screening software engineers or data scientists. We’ve watched a lot of companies learn this the hard way. The traditional coding interview tells you almost nothing about whether someone can keep a model reliable in production.
Here’s what we look for, and what we’d recommend you look for too.
For MLOps Engineers
Ask about production incidents. Seriously. The best MLOps engineers will tell you about a time a model degraded, how they detected it, what they changed in the monitoring or pipeline to stop it from happening again. Specifics matter. If someone can’t walk you through a real production issue they handled, they might be a DevOps engineer who added MLOps to their LinkedIn headline. That’s a different thing entirely.
Also, screen for systems thinking over tool knowledge. Knowing MLflow is fine. Understanding why you’d pick it over another option for a specific team size and workload pattern is what separates strong hires from mediocre ones. The tools change constantly. The reasoning behind good decisions doesn’t.
For ML Engineers Moving Into Production
The question that tells you the most: how would you handle a model that performs great on holdout data but degrades after two weeks in production? Strong candidates immediately think about data drift, feature freshness, population shifts, and feedback loops. Weaker ones just say they’d retrain with more data. That’s a red flag.
For DevOps Engineers Moving Into ML
The technical gap between DevOps and ML infrastructure is bridgeable. The mindset gap isn’t always. A DevOps engineer who asks good questions about model serving patterns, GPU resource management, and data pipeline architecture is usually a better bet than someone who knows Kubernetes backwards and forwards but treats ML models as just another container to push.
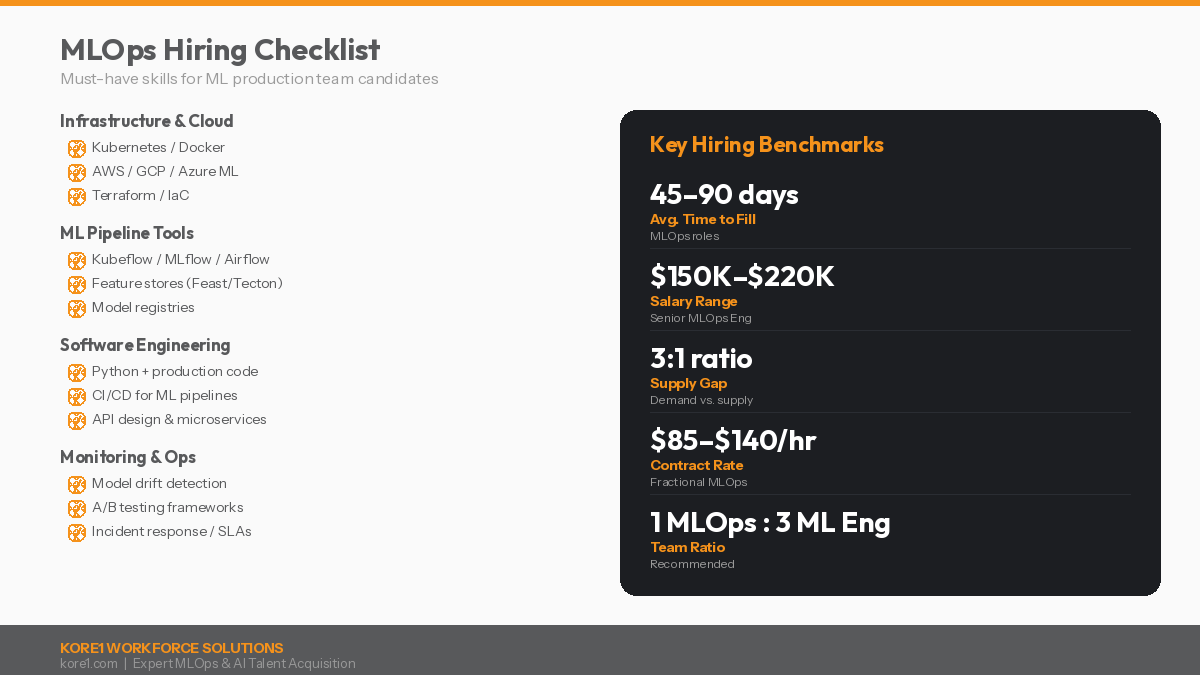
Must-have skills and market benchmarks for hiring MLOps engineers and ML production team members.
What You’ll Actually Pay for MLOps Talent in 2026
Let’s talk money, because this is where a lot of hiring plans quietly fall apart. Budgets get set based on general engineering salaries, and then the first MLOps candidate laughs at the offer.
The data from Glassdoor, collected from reported salaries as of January 2026, paints a pretty clear picture. Average MLOps Engineer base salary in the U.S. is about $161,000 per year. The 25th percentile sits around $132,000 and the 75th percentile hits nearly $200,000. Senior MLOps Engineers average $203,000, and top earners clear $250,000 plus equity.
PwC’s Global AI Jobs Barometer found that workers with AI skills now earn up to 56% more than peers in the same roles. That premium more than doubled from 25% just a year earlier. MLOps engineers are right in that sweet spot because the demand dramatically outstrips supply, and qualified candidates know exactly what they’re worth.
LinkedIn’s data showed MLOps growing at roughly 10x over five years, making it one of the fastest-emerging job categories in tech. And from what we see on the recruiting side, multiple competitive offers within 48 hours are now normal for experienced candidates. If your interview process takes six weeks, you’re not going to close your top pick. Probably not your second pick either.
Building Your MLOps Hiring Plan
Knowing the roles and salaries is step one. Actually executing the plan is where it gets hard. Here are the things we tell clients who are building production ML teams for the first time.
Be specific in your job descriptions. The most common failure in MLOps hiring is a posting that blends three roles into one. If your listing asks for deep learning research, Kubernetes administration, and data pipeline engineering in the same person, you’re going to attract generalists who can’t go deep on any of it. Pick one role. Hire for that. Then hire the next one.
Move faster than you think you need to. Top MLOps candidates are off the market in two to three weeks. We see the best hiring processes close senior MLOps roles in 14 to 20 days from first screen to signed offer. If yours takes longer than that, you need to cut steps or parallelize your interview stages.
Test for production thinking, not tool checklists. Someone who shipped three models to production on AWS is more valuable than someone with certifications in AWS, GCP, and Azure who has never monitored a live model. Screen for real deployments, real incidents, real tradeoffs.
Consider contract-to-hire. When you’re building an MLOps function from scratch, the role definition often evolves as the team matures. Contract-to-hire lets you bring in vetted talent quickly while you figure out exactly what the permanent version of the role looks like. It’s a practical middle ground that reduces risk on both sides.
Work with a staffing partner who actually understands ML roles. And yes, we’re biased here. But the reality is that most general tech recruiters can’t tell the difference between an MLOps engineer, a data engineer, and an ML engineer. Those are different jobs with different skills. Getting the screening wrong costs months in lost productivity. A partner that specializes in AI and ML staffing compresses your timeline and catches mismatches before they become expensive mistakes.
Frequently Asked Questions
What’s the difference between DevOps and MLOps?
DevOps is about automating software development and deployment. MLOps takes those same principles and applies them to machine learning, which brings a whole set of extra challenges. You’re dealing with data versioning, experiment tracking, model monitoring, drift detection, and retraining schedules. Both use CI/CD and containers, but MLOps has to account for the fact that model behavior depends on data, not just code. That’s a fundamentally different problem.
When should we hire our first MLOps engineer?
Sooner than you think. Most companies we work with should have hired one after their second ML engineer came on board, or once they had three models running in production. The telltale signs: deployments that take weeks instead of days, ML engineers who spend more time on infrastructure than on modeling, and nobody watching for performance regressions after launch.
What skills should an MLOps engineer have?
Python. Docker and Kubernetes. CI/CD pipeline design. At least one major cloud platform. Experiment tracking tools like MLflow. And, this is the big one, a real understanding of the ML model lifecycle beyond just deployment. The best ones know how to set up automated retraining, drift detection, and monitoring that actually catches problems. Not just deploy models as static artifacts and hope for the best.
How much does an MLOps engineer cost in 2026?
Average base salary sits around $161,000 in the U.S. right now, based on Glassdoor data from January 2026. The range is wide though. Entry-level or mid-career, you might get someone at $130,000 to $140,000. Senior talent with real production experience is going to run $200,000 or more. And at the big tech companies, total comp packages go well beyond that.
Which ML production team roles should a mid-size company prioritize?
If you have three to ten models in production, start with an MLOps Engineer, a Data Engineer focused on ML pipelines, and an ML Engineer with real deployment experience. Add a DevOps engineer with ML infrastructure skills when budget allows. The Platform Engineer and Architect roles become important once you’re past ten models and managing multiple teams.
Why do most ML models never reach production?
The reasons are mostly organizational, not technical. Lack of ML engineering leadership. Gaps between data science teams and the engineering teams that handle deployment. Inconsistent environments between development and production. And almost nobody monitors models after they’re launched, so problems pile up silently. Hiring dedicated MLOps and production ML talent is the most direct way to fix these issues.