Hiring a data engineer in 2026 means competing in a talent market where qualified candidates are genuinely scarce, salaries keep climbing, and the best people rarely need to apply for anything. This guide covers realistic salary benchmarks, which technical skills to prioritize, the hiring mistakes that cost companies the most time, and when bringing in a specialized data engineer staffing agency actually makes sense.
I want to be upfront about the lens I’m writing through. We place data engineers. We talk to hiring managers about this literally every week. And the conversations almost always start the same way. We need someone good. We needed them last month. And we keep getting outbid.
If that’s you, keep reading. If you’re just starting to think about building a data team, even better. You’ll avoid some painful lessons.
The Data Engineering Talent Market Is Worse Than You Think
I know everyone says their market is tight. Recruiters especially. But data engineering is a different animal right now. Industry estimates put global data-related job vacancies somewhere around 2.9 million, and demand specifically for data engineers is growing at roughly 23% year over year. Those numbers have been climbing for a while. What changed recently is the why.
Everyone went all in on AI.
Which, fine. Makes sense. But a lot of companies skipped a step. They hired data scientists, started building models, got excited about the results they saw in notebooks. And then nothing made it to production. Because the data infrastructure wasn’t there. The pipelines were messy. The warehouse was a disaster. The boring foundational work that nobody wanted to invest in? Turns out you can’t skip it.
We see this pattern constantly. A company spends six figures on AI talent, gets frustrated when nothing ships, and eventually realizes the bottleneck was never the models. It was the plumbing. That’s what data engineers do. Build the plumbing. And suddenly everybody needs a plumber.
The result is a scramble. Companies that should have hired data engineers before data scientists are now trying to backfill those roles in a market where good candidates already have three offers on the table. Good luck doing that with a generic Indeed posting and a four-round interview process that takes two months.
What Data Engineers Actually Earn Right Now
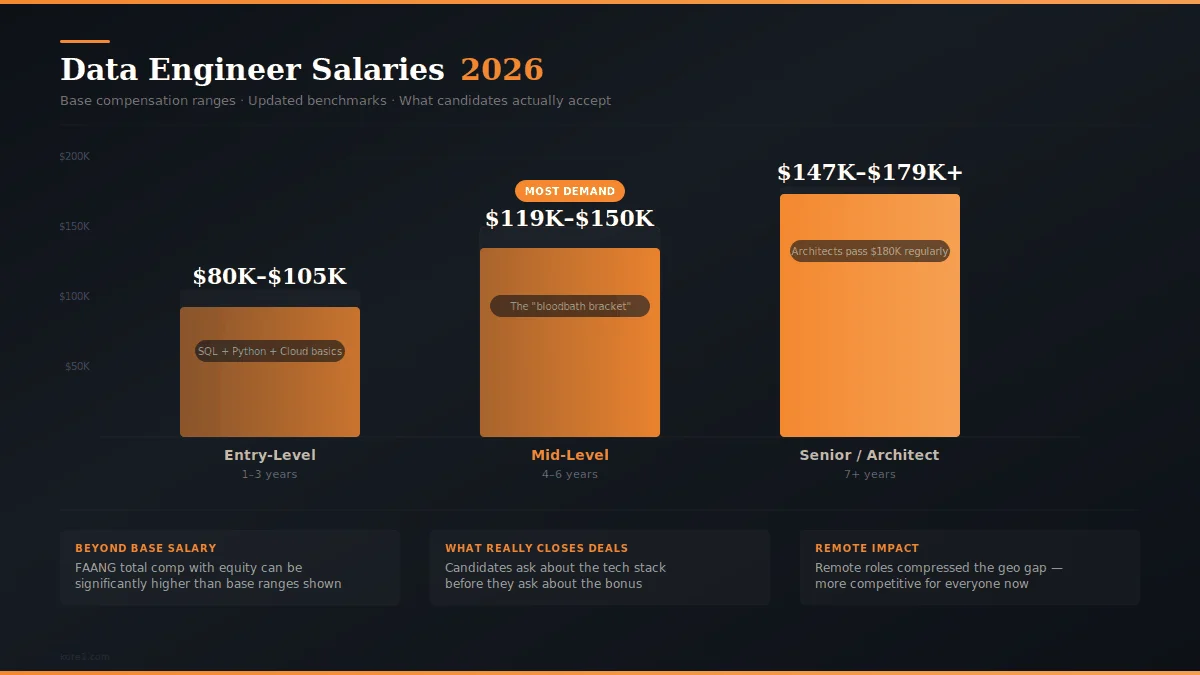
Compensation is usually the first question hiring managers ask us. The answer tends to make people a little uncomfortable. If you haven’t benchmarked in the last six months, your numbers are probably stale. Salaries moved again.
| Experience Level | Base Salary Range | What We’re Seeing |
|---|---|---|
| Entry-Level, 1-3 yrs | $80K – $105K | Solid SQL and Python, maybe some cloud exposure |
| Mid-Level, 4-6 yrs | $119K – $150K | The bloodbath bracket. Everyone wants this person. |
| Senior, 7+ yrs | $147K – $179K+ | Architects blow past $180K regularly |
Those are base numbers only. At FAANG-level companies and well-funded startups, total comp with equity and bonuses gets a lot higher. And yes, location still matters. San Francisco and New York command premiums. But remote roles have compressed the gap in a way that’s made things more competitive for everybody, even companies that thought being outside a tech hub gave them a quieter talent pool to draw from.
Here’s the part that surprises a lot of hiring managers though. Salary alone usually isn’t what closes the deal. We hear this from candidates constantly. They ask about the tech stack before they ask about the bonus. They want to know if they’ll be building on modern tools or babysitting some legacy system that should have been retired in 2019. They want to know if the work actually matters.
If you’re not sure what’s driving decisions for candidates in your specific market, talking to a specialized data engineer staffing firm is a fast way to get that kind of intel.

The Skills That Actually Matter When Hiring Data Engineers
The skill set has expanded quite a bit. I’ll break it down the way we actually think about it when we’re evaluating candidates. Not the sanitized job description version. The real version.
The stuff you can’t skip
SQL and Python. Period. SQL shows up in basically every data engineering job posting. Python appears in roughly 78% of data science postings, which overlaps heavily with data engineering. But don’t just check boxes. You want someone who can write advanced SQL. Window functions, query optimization, complex joins across huge datasets. Not someone who learned SELECT * FROM in a bootcamp three months ago. On the Python side, look for PySpark experience, Pandas, and the ability to build and maintain APIs.
Cloud fluency is non-negotiable at this point. Over 94% of enterprises are on the cloud in some form, so your data engineer needs to know their way around at least one major platform. AWS still leads the pack. Azure has been gaining ground with enterprise shops. GCP attracts the AI-heavy crowd, especially teams running BigQuery. Don’t require all three unless you actually use all three. (You probably don’t.)
And then the pipeline and warehousing layer. This is the core of the job. Snowflake, Databricks, dbt, Apache Airflow. Someone who can think about data modeling, design schema architecture, and build ETL pipelines that don’t fall over at 3 AM. This is where you see the biggest gap between a mediocre hire and a genuinely good one.
What’s getting more important fast
AI fluency. And I don’t mean as a resume buzzword. Data engineers increasingly need to build pipelines that feed machine learning models, work with vector databases, and use AI-assisted development tools as part of their daily workflow. If you’re also investing in AI and ML engineering talent, your data engineers need to speak that language or the two groups will end up in different galaxies.
Real-time streaming keeps climbing in importance. Apache Kafka, Spark Streaming. Two years ago this was a nice-to-have on most of our job specs. Now it shows up in maybe a third of them. Event-driven architectures are becoming the default for a lot of companies, and the data engineers who can build in that world are commanding premiums.
DevOps and DataOps practices have crept into data engineering in a big way too. CI/CD for data pipelines. Infrastructure-as-code. Containerization. Automated testing. Engineers who bring that operational mindset add a ton of value. Especially on teams where deployment speed and reliability aren’t just nice-to-haves but actual requirements.
The thing nobody puts on a job description but everybody needs
Communication skills. I know. Boring answer. But the best data engineers we’ve placed can sit in a room with a product manager or VP and translate messy business requirements into a technical plan without making anyone feel dumb. That skill is wildly undervalued in most hiring processes. I’ve seen companies pass on excellent communicators because their Spark knowledge was slightly weaker than another candidate’s, then spend six months dealing with an engineer who builds great pipelines but can’t explain what they’re doing to anyone outside of engineering. Don’t make that mistake.
Hiring Strategies That Actually Work
Speed wins. That is the single most important piece of advice I can give you about hiring data engineers in 2026. The companies that move quickly get the best candidates. The rest get whoever is left. I’ve barely exaggerated that.
Your interview process is probably too long
If your process takes more than three weeks from first screen to offer, you’re losing people. That is not an exaggeration. We watch it happen in real time. A client takes five days to schedule the second round. Then a week for the panel interview. Then the hiring committee needs to meet. And by the time they’re ready to extend an offer, the candidate accepted something else two days ago.
Take an honest look at your rounds. Is every single one necessary? Can you combine the technical assessment and the culture conversation into one session? Are you giving feedback between stages or just leaving people in silence? The belief that good candidates will patiently wait for you is probably the most expensive myth in tech hiring right now.
Lead with your tech stack
This is maybe the most underused recruiting advantage I see. Companies running modern tools like dbt, Databricks, Snowflake, and Airflow see noticeably faster offer acceptance. Engineers want to work with good technology. They want to build things. Not maintain some legacy monolith they inherited from a team that left in 2021.
If your stack includes some legacy systems, that’s okay. Most do. Just be transparent. Tell the candidate what the modernization roadmap looks like and what their role in it would be. That pitch, done honestly, can be more compelling than a fully modern stack with no interesting problems to solve. Engineers like to fix things. Give them something worth fixing.
Don’t default to full-time for everything
Contract and contract-to-hire models have gained real traction in data engineering. For good reason. You move faster. You evaluate someone on actual work before making a permanent commitment. And you can scale based on project needs instead of guessing a year out.
This is especially true for specialized work. If you need someone with a specific cloud certification or niche domain experience, a data scientist and data engineer staffing partner can get you in front of pre-vetted candidates who are ready to go. That speed advantage compounds fast when you’re filling multiple seats. And it takes the pressure off your internal IT staffing team so they can focus on permanent headcount.
When Does It Make Sense to Use a Staffing Partner?
Bias disclosure. I work at a staffing firm. So take this section with the appropriate grain of salt. That said, I’m also going to be honest about when you probably don’t need us.
If you have a strong internal recruiting team, plenty of time, and the role isn’t particularly specialized? You’re probably fine on your own. Save the money.
But there are situations where doing it alone costs you more than bringing in help. A lot more.
If you’re on a tight deadline and need someone quickly, a staffing partner with a live pipeline of vetted data engineers can shave weeks off your search. We’ve filled roles in days that internal teams had been working for months. Not because we’re smarter. Because we already knew the candidates. They were already in our network.
If you need a very specific skill set, like a particular cloud certification, experience with ML infrastructure, or deep knowledge of a niche industry, generalist job boards aren’t going to cut it. Specialized recruiters maintain relationships with passive candidates. The ones who aren’t browsing LinkedIn. The ones you literally cannot reach with a job posting.
And if you’re scaling a data team rapidly, whether from new funding, a big initiative, or a pivot, handling five simultaneous searches internally gets overwhelming in a hurry. That’s where a partner earns their fee.
When you’re evaluating staffing firms, look for real data engineering expertise. Not a generalist agency that “also does tech.” The right partner asks detailed questions about your architecture, your data stack, and your team culture before they ever send a resume. If they don’t ask those questions, they’re not going to send you the right people. Simple as that.
Mistakes We See Over and Over
I could write a whole separate post on this. Maybe I will. But here are the ones that cost companies the most.

Blending data roles in the job description. A data engineer is not a data scientist is not a data analyst. They use different tools. They solve different problems. When a job description tries to be all three, you attract people who aren’t quite any of them. Get clear on what you actually need before you post. If you’re unsure, talk to someone who hires for these roles regularly. We wrote a whole guide on how to screen technical candidates that covers this in more detail.
Filtering too hard on specific tools. You use Snowflake. Great. Does the candidate absolutely need to have used Snowflake, or do they have deep warehousing fundamentals and the ability to pick up new tools quickly? Nine times out of ten it’s the second one. Over-filtering on brand names shrinks your candidate pool for no real reason. A good engineer with five years of Redshift experience can learn Snowflake in a couple weeks.
Glacial feedback between stages. Already hit this one but it’s worth saying twice. Every silent day between interview rounds is a day your best candidate is talking to someone else. Build decision timelines into the process. Then actually follow them.
Ignoring soft skills entirely. Data engineers work with analysts, data scientists, product managers, executives. If someone can’t collaborate or communicate, the technical chops don’t matter as much as you think. I’ve seen brilliant engineers crater team morale in weeks. Assess for it.
Chasing the unicorn. Expert in every cloud platform, every pipeline tool, every language, plus five years of Kubernetes and a master’s degree. For $140K. Come on. That person either doesn’t exist or will cost you $250K minimum. Be realistic about your must-haves versus your wish list. You’ll fill the role in half the time.
Keeping Data Engineers After You’ve Hired Them
Quick section on retention because it connects directly to everything above. Getting people in the door is only half the battle. Keeping them is the other half. And in this market, you really cannot afford to be complacent about it.
The data engineers we talk to want three things consistently. Clear career path. Modern tools. Work that ships and matters. If you deliver on those three, you’ll hold onto people much longer than the industry average. If you can’t? Even top-of-market salary won’t keep someone who feels stuck writing the same pipeline for the third year running.
Team structure matters here too. A mix of senior engineers who architect and mentor, mid-level engineers doing the core execution, and juniors growing into bigger responsibilities. That pyramid creates knowledge transfer, resilience, and built-in career ladders. Which helps retention. Which helps everything. We’ve written about similar team architecture in the context of building ML engineering teams, and the principles carry over directly.
One more thing. Stay connected to the market even when you don’t have an open req. Build relationships with recruiters before you’re desperate. Attend meetups and conferences. Keep your employer brand visible. The companies that treat hiring as an ongoing practice instead of a fire drill are the ones that consistently get the best people. Every time.
Ready to Build Your Data Engineering Team?
Hiring data engineers in 2026 takes competitive comp, a process that doesn’t waste people’s time, and usually the right partner. The companies getting this right are the ones that move quickly, offer real opportunities, and understand what today’s data professionals actually care about.
At KORE1, we’ve been doing this for years. Our recruiters understand modern data stacks, know how to evaluate technical candidates properly, and work as an extension of your team. We’re not a resume mill. We’re a partner that asks hard questions before we send you a single candidate.
Talk to a KORE1 recruiter today and get access to pre-vetted data engineers who can start making an impact fast.
Frequently Asked Questions
How long does it typically take to hire a data engineer?
If you’re doing it internally? Anywhere from 45 to 90 days is normal. Senior roles and niche specializations take longer. Sometimes a lot longer. Working with a specialized staffing partner compresses that because you’re starting with a pipeline of people who’ve already been vetted. We’ve closed placements in under two weeks when the timing lined up. But I wouldn’t call that typical. Realistic timeline with a partner is three to six weeks for most roles.
What’s the actual difference between a data engineer and a data scientist?
The analogy I keep coming back to. Data engineers build the roads. Data scientists drive on them. Engineers handle pipelines, warehouses, ETL processes, infrastructure. Scientists analyze the data that flows through all of that and build predictive models on top of it. Both are critical. But they’re different jobs requiring different backgrounds and different interviews. Mixing them up in a job posting is one of the fastest ways to tank your search.
Should I hire full-time or go the contract route?
Depends entirely on the situation. Ongoing infrastructure work with a long-term roadmap? Full-time makes sense. Specific project with a clear end date? Contract. Not sure yet and want to evaluate someone on real work before committing? Contract-to-hire is built for exactly that. A lot of the companies we work with use a mix. Permanent core team plus contract specialists for specific initiatives. There’s no one right answer here.
Which cloud platform matters most?
Whichever one you run on. That’s the honest answer. But if you’re flexible and asking which gives a candidate the broadest marketability, AWS is still the default. Azure is growing fastest in enterprise environments. GCP is strong for AI-focused shops. More important than the specific platform is whether someone understands cloud-native architecture and can learn a new console without hand-holding. Platform-specific syntax is learnable. Architectural thinking isn’t.
We can’t compete on salary with the big tech companies. Now what?
You’d be surprised how many strong engineers actually prefer mid-size companies. More ownership. Broader scope. You can see the impact of your work instead of owning one microservice in a system of ten thousand. Lead with that. Lead with your stack, your culture, and the problems you’re solving. And move fast. I can’t stress this enough. Speed might be the single biggest advantage a smaller company has over a Google or an Amazon in recruiting. They have bureaucracy. You have agility. Use it.